

 Android & iPhone
Android & iPhone写在 GTC 大会之后 Web3 能拯救 AI 算力吗?

佐爷歪脖山
刚刚
云算力的复活——以 AI 之名
时尚是个循环,Web 3 也是。
Near “重新”成为 AI 公链,创始人 Transformer 作者之一身份让其得以出席英伟达 GTC 大会,和皮衣老黄畅谈生成式 AI 的未来,Solana 作为 io.net、Bittensor、Render Network 的聚居地成功转型为 AI 概念链,此外还有 Akash、GAIMIN、Gensyn 等涉及 GPU 计算的异军突起者。
如果我们将视线抬高,在币价上涨之余,可以发现几个有趣的事实:
GPU 算力之争来到去中心化平台,算力越多,等同于计算效果越强,CPU、存储和 GPU 互相搭售;
计算范式从云化到去中心化过渡中,背后是 AI 训练到推理的需求转变,链上模型不再是空玄之谈;
互联网架构的底层软硬件组成和运行逻辑并未发生根本改变,去中心化算力层更多承担激励组网作用。
先进行概念区分,Web3 世界的云算力诞生于云挖矿时代,指将矿机的算力打包出售,免去用户购买矿机的巨额支出,但是算力厂商经常会“超售”,比如将 100 台矿机算力混合出售给 105 个人,以获取超额收益,最终让该词等同于骗人。
本文中的云算力特指基于 GPU 的云厂商的算力资源,这里的问题是去中心化算力平台究竟是云厂商的前台傀儡还是下一步的版本更新。
传统云厂商和区块链的结合比我们想象的要深,比如公链节点、开发和日常存储,基本上都会围绕着 AWS、阿里云和华为云来展开,免去购买实体硬件的昂贵投资,但是带来的问题也不容忽视,极端情况下拔网线就会造成公链宕机,严重违背去中心化精神。
另一方面,去中心化算力平台,要么直接搭建“机房”以维护网络稳健性,要么直接搭建激励网络,比如 IO.NET 的空投促 GPU 数量策略,一如 Filecoin 的存储送 FIL 代币,出发点不是满足使用需求,而是进行代币赋能,一个证据是大厂、个人或学术机构甚少会真正使用它们来进行 ML 训练、推理或图形渲染等工作,造成严重的资源浪费。
只不过在币价高涨和 FOMO 情绪面前,一切对去中心化算力是云算力骗局的指责都烟消云散了。
推理和 FLOPS,量化 GPU 计算能力
AI 模型的算力需求正从训练到推理演进。
先以 OpenAI 的 Sora 为例,虽然也是基于 Transformer 技术制造而来,但是其参数量相较于 GPT-4 的万亿级,学界推测在千亿级以下,杨立昆更是说只有 30 亿,即训练成本较低,这也非常好理解,参数量小所需要的计算资源也等比例的衰减。
但是反过来,Sora 可能需要更强的“推理”能力,推理可以理解为根据指令生成特定视频的能力,视频长期被视为创意内容,因此需要 AI 更强的理解能力,而训练相对简单一些,可以理解为根据已有的内容总结出规律,无脑堆算力,大力出奇迹。
在以往阶段,AI 算力主要用于训练层面,少部分用于推理能力,并且基本都被英伟达各类产品包圆,但是在 Groq LPU(Language Processing Unit)面世后,事情开始起变化,更好的推理能力,叠加大模型的瘦身和精度提高,有脑讲逻辑,正在慢慢成为主流。
另外还要补充下 GPU 的分类,经常能看到是臭打游戏的拯救了 AI,这话有理的地方在于游戏市场对高性能 GPU 的强烈需求覆盖了研发成本,比如 4090 显卡,打游戏的和 AI 炼丹的都能用,但是要注意的是,慢慢的游戏卡和算力卡会逐步解耦,这个过程类似于比特币矿机从个人电脑发展到专用矿机,其所用的芯片也遵循从 CPU、GPU、FPGA 和 ASIC 的顺序。
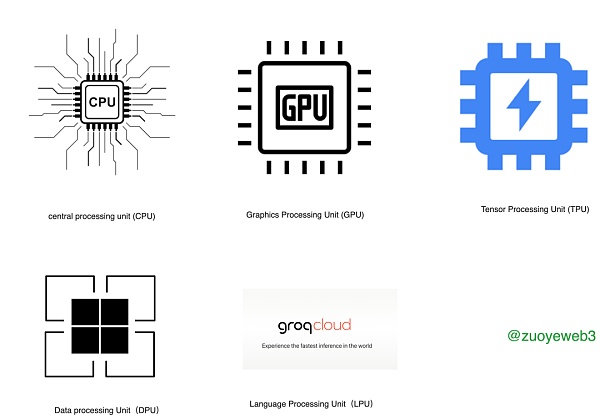
随着 AI 技术,尤其是 LLM 路线的成熟和进步,更多 TPU、DPU 和 LPU 的类似尝试会越来越多,当然,目前主要产品还是英伟达家的 GPU,下文所有的论述也是基于 GPU,LPU 等更多是对 GPU 的一种补充,完全取代尚需时日。
去中心化算力竞赛不争抢 GPU 的拿货渠道,而是尝试建立新的盈利模式。
行文至此,英伟达快成了主角,根本上是英伟达占据了显卡市场的 80% 份额,N 卡和 A 卡之争只存在理论上,现实中大家都是口嫌体正直。
绝对的垄断地位,造就了各家争抢 GPU 的盛况,从消费级的 RTX 4090 到企业级的 A100/H100 都是如此,各家云厂商更是囤货主力。但是 Google、Meta、特斯拉和 OpenAI 等涉及 AI 公司都有自制芯片的行动或计划,而国内企业已经纷纷转向华为等国产厂商,GPU 赛道仍然拥挤异常。
对于传统云厂商而言,出售的实际上是算力和存储空间,所以用不用自己的芯片没有 AI 公司那么紧迫,但是对于去中心化算力项目而言,目前处于前半截,即跟传统云厂商抢算力生意,主打廉价和易得,但是未来会不会像比特币挖矿一样,出现 Web3 AI 芯片几率不大。
额外吐槽一句,自从以太坊转 PoS 之后,币圈的专用硬件已经越来越少,Saga 手机、ZK 硬件加速和 DePIN 等市场规模太小,希望去中心化算力能为专用 AI 算力卡探索出一条 Web3 特色道路。
去中心化算力是云的下一步还是补充。
GPU 的运算能力,业界通常以 FLOPS (Floating Point Operations Per Second,每秒浮点运算次数)比较,这是最常用的计算速度的的指标,不论 GPU 的规格还是应用并行等优化措施,最终都以 FLOPS 论高低。
从本地计算到上云,大约进行了半个世纪,而分布式概念从计算机诞生之初便存在,在 LLM 的推动下,去中心化和算力结合,不再像以往那般虚无缥缈,我会尽可能多总结现有的去中心化算力项目,考察维度只有两点:
GPU 等硬件数量,即考察其计算速度,根据摩尔定律, 越新 GPU 的计算能力越强,相等规格下数量越多则计算能力越强;
激励层组织方式,这属于 Web3 的行业特色,双代币、加治理功能、空投激励措施等,更简易明白各项目的长期价值,而非过度关注短期币价,长期只看能拥有或者调度多少 GPU。
从这个角度而言,去中心化算力依然是基于“现有硬件+激励网”的 DePIN 路线,或者说互联网架构依然是底层,去中心化算力层是“硬件虚拟化”后的货币化,重在无准入的访问,真正组网依然需要硬件的配合。
算力要去中心化,GPU 要集中化
借助区块链三难困境框架,去中心化算力的安全性不必特殊考虑,主要是去中心化和可扩展性,后者即是 GPU 组网后的用途,目前处于 AI 一骑绝尘的状态。
从一个悖论出发,如果去中心化算力项目要想做成,那么其网络上的 GPU 数量反而要尽可能的多,原因无他,GPT 等大模型的参数量爆炸,没有一定规模的 GPU 无法具备训练或推理效果。
当然,相对于云厂商的绝对控制,当前阶段,去中心化算力项目至少可以设置无准入和自由迁移 GPU 资源等机制,但是出于资本效率的提升,未来会不会形成类似矿池的产物也说不定。
在可扩展性,GPU 不仅可用于 AI 方面,云电脑和渲染也是条可行路径,比如 Render Network 便专注于渲染工作,而 Bittensor 等专注于提供模型训练,更直白的角度,可扩展性等同于使用场景和用途。
所以可在 GPU 和激励网外额外加两个参数,分别是去中心化和可扩展性,组成四个角度的对比指标,请大家注意,这种方式和技术对比不同,纯粹是图一乐。

在上述项目中,Render Network 其实非常特殊,本质上其是分布式渲染网络,和 AI 的关系并不直接,在 AI 训练和推理中,各环节环环相扣,不论是 SGD(随机梯度下降,Stochastic Gradient Descent)还是反向传播等算法都要求前后一致,但是渲染等工作其实不必非要如此,经常会对视频和图片等进行切分便于任务分发。
其 AI 训练能力主要和 io.net 并网而来,作为 io.net 的一种插件而存在,反正都是 GPU 在工作,怎么干不是干,更有前瞻性的是其在 Solana 低估时刻的投奔,事后证明 Solana 更适合渲染等网络的高性能要求。
其次是 io.net 的暴力换 GPU 的规模发展路线,目前官网列出足足 18 万块 GPU,在去中心化算力项目中处于第一档的存在,和其他对手存在数量级的差异,并且在可扩展性上,io.net 聚焦于 AI 推理,AI 训练属于顺带手的工作方式。
严格意义上而言,AI 训练并不适合分布式部署,即使是轻量级的 LLMs,绝对参数量也不会少到哪里去,中心化的运算方式在经济成本上更为划算,Web 3 和 AI 在训练上的结合点更多是数据隐私和加密运算等,比如 ZK 和 FHE 等技术,而 AI 推理 Web 3 大有可为,一方面,其对 GPU 运算性能相对要求不高,可以容忍一定程度的损耗,另一方面,AI 推理更靠近应用侧,从用户角度出发进行激励更为可观。
另外一家挖矿换代币的 Filecoin 也和 io.net 达成 GPU 利用协议,Filecoin 将自身的 1000 块 GPU 和 io.net 并网使用,也算是前后辈之间的携手共进了,祝两位好运。
再次是也未上线的 Gensyn,我们也来云测评一下,因为还处于网络建设早期,所以还未公布 GPU 数量,不过其主要使用场景是 AI 训练,个人感觉对高性能 GPU 的数量要求不会少,至少要超过 Render Network 的水平,相比于 AI 推理,AI 训练和云厂商是直接的竞对关系,在具体机制设计上也会更为复杂。
具体来说,Gensyn 需要保证模型训练的有效性,同时为了提升训练效率,因此大规模使用了链下计算范式,所以模型验真和防作弊系统需要多方角色博弈:
Submitters:任务发起者,最终为训练成本付费。
Solvers:训练模型,并提供有效性证明。
Verifiers:验证模型有效性。
Whistleblowers:检查验证者工作。
整体而言,运作方式类似 PoW 挖矿 + 乐观证明机制,架构非常复杂,也许将计算转移至链下可以节省成本,但是架构的复杂度会带来额外运行成本,在目前主要去中心化算力聚焦 AI 推理的关口,在这里也祝 Gensyn 好运。
最后是老骥伏枥的 Akash,基本上和 Render Network 一同起步,Akash 聚焦 CPU 的去中心化,Render Network 最早聚焦于 GPU 的去中心化,没想到 AI 爆发后双方都走到了 GPU + AI 计算的领域,区别在于 Akash 更关注推理。
Akash 焕发新春的关键在于看中了以太坊升级后的矿场问题,闲置 GPU 不仅可以以女大学生二手自用的名义挂闲鱼,现在还可以一起来搞 AI,反正都是为人类文明做贡献。
不过 Akash 有个好处是代币基本上全流通,毕竟是很老的老项目了,也积极采纳 PoS 常用的质押系统,但是怎么看团队都比较佛系,没有 io.net 那么高举猛打的青春感。
除此之外,还有边缘云计算的 THETA,提供 AI 算力的细分领域解决方案的 Phoenix,以及 Bittensor 和 Ritual 等计算旧贵新贵,恕版面限制不能一一列举,主要是有些实在是找不到 GPU 数量等参数。
结语
纵观计算机发展历史,各类计算范式的都可以建设去中心化版本,唯一的遗憾是他们对主流应用没有任何影响,目前的 Web3 计算项目主要还是在行业内自嗨,Near 创始人去 GTC 大会也是因为 Transformer 的作者身份,而不是 Near 的创始人身份。
更悲观的是,目前的云计算市场的规模和玩家都过于强大,io.net 能取代 AWS 吗,如果 GPU 数量足够多倒是真的有可能,毕竟 AWS 也长期使用开源的 Redis 当底层构件。
某种意义上而言,开源和去中心化的威力一致未能等量齐观,去中心化的项目过度集中在 DeFi 等金融领域,而 AI 也许是切入主流市场的一个关键路径。
 1
1
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。

24小时热文


 SEC主席九论AI与加密创新:牢记任务、回归使命
SEC主席九论AI与加密创新:牢记任务、回归使命数字新财报

 x402的v2版本
x402的v2版本Block unicorn
 通胀裂变下的美国经济未来
通胀裂变下的美国经济未来周子衡

 为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析
为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析Stablehunter
 美国SEC手把手教你怎么托管加密资产
美国SEC手把手教你怎么托管加密资产金色财经

 山寨季指数跌至新低 市场真的变了?
山寨季指数跌至新低 市场真的变了?区块链骑士
- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部