

 Android & iPhone
Android & iPhoneDeepSeek暴击英伟达 震惊特朗普

碳链价值
刚刚
作者:秦晋;来源:碳链价值
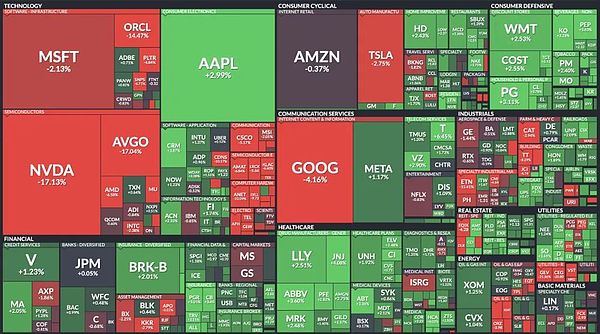
让硅谷大佬和华尔街精英们万万没想到的是,一股来自东方的神秘力量DeepSeek居然能让美国股市及其巨额财富在一夜之间实现史诗级下跌和缩水。1月28日,据相关数据显示,美股芯片股一夜之间蒸发掉1万亿美元。英伟达市值单日蒸发掉6000亿美元,创美股最高记录。就连美国总统特朗普也按奈不住出来发表一番评论。他表示,中国人工智能应用DeepSeek的突然崛起「应该给美国科技公司敲响警钟」,并表示中国公司开发出更便宜、更高效的人工智能模型是件好事。
特朗普表示,他仍然预计美国科技公司将在人工智能领域占据主导地位,但他承认低成本人工智能助手DeepSeek带来的挑战。DeepSeek在过去的周末飙升至苹果应用商店第一名。
接下来的问题是,这仅仅是开始吗?
1月28日,据英国《金融时报》报道,一家鲜为人知的中国对冲基金向人工智能领域投掷一枚重磅炸弹。他们开发的人工智能大模型实际上与市场领导者Sam Altman的OpenAI旗鼓相当,但成本却只有后者的零头。OpenAI将其模型的工作原理视为专有技术,而DeepSeek的R1则将技术核心进行开源,从而吸引了开发人员使用和在此基础上进行开发。
在周一美国股市开盘前,人工智能领域最大的5家科技股——英伟达、Alphabet、亚马逊、微软以及Meta Platforms——市值合计蒸发近7500亿美元。如果DeepSeek真的在没有使用其最先进芯片的情况下获胜,那么对英伟达来说可能尤其严峻。
而在美股开盘后:芯片股英伟达跌幅高达17.5%。博通跌幅高达达16.5%。台积电跌幅达14.3%。美光跌幅达10.5%。Arm跌幅达 10.0%。AMD跌幅达5.6%。上述芯片股在一天内就跌去近 1 万亿美元市值。其中英伟达已经跌去自10月2日以来的所有涨幅,在两个交易日内下跌21%。英伟达市值已下跌6300 亿美元。这是上周世界上最大的上市公司,在两天内跌去五分之一价值。黄仁勋个人身价也随之缩水1000亿美元。
包括芯片制造商ASML在内的科技公司和能源公司的投资者原本希望数据中心的发展能够推动公司业绩增长,现在却担心自己的投资会付诸东流。根据Visible Alpha估计,超大型公司今年将投入近3000亿美元用于资本支出。分析师预计,在周三公布财报时,Meta和微软将报告2024年的投资总额为940亿美元。
有外媒分析表示,人工智能竞赛已经开始。让英伟达股价崩溃的原因显然包括,DeepSeek已成为人工智能创新的领导者,英伟达称其为「卓越的人工智能进步」。
其次,从理论上讲,人工智能进步对英伟达来说是利好,因为这意味着更多的芯片需求。问题是DeepSeek在中国,而美国正在对中国进行芯片技术封锁。这意味着英伟达只能向DeepSeek大量出售性能较弱的H800芯片,而不能出售每颗售价超过3万美元的H100芯片。即使DeepSeek只持有性能较低的芯片,中国也能有效地生成一种成本降低96%且效率更高的AI模型,价格也降低了90%以上。
同时,他们的AI模型是免费的,而像ChatGPT这样的AI模型相对昂贵(每月200美元以上),效率也较低。看来中国已经开始以以前认为不可能的速度进行创新。美国科技界认为其主导地位无法被取代。美国的大盘科技股现在正面临现实,他们可以免费获得更好的AI模型,而且只会越来越好。为什么要为更差的产品支付溢价呢?
接下来的反应可能是美国限制DeepSeek或向中国出口芯片(我们已经看到几个月了),但这显然行不通。如果英伟达能够找到一种方法来利用DeepSeek的发展带来的新需求,那么这次下跌将被视为一种礼物。最终,人工智能在硬件和软件方面的竞争将加剧,没有公司会是「安全的」,创新的速度只会加快。
那么DeepSeek取胜是原因是什么?以及未来人工智能会如何展开?
美国投资公司Atreides管理合伙人Gavin Baker从多个维度对DeepSeek以及人工智能未来演进趋势进行了分析。马斯克称赞这是自己见过的最好的分析。
Gavin Baker表示,最重要的是,DeepSeek R1比Open ai o1便宜得多,推理效率也更高,这不是从600万美元的训练数据中得出的。R1在每个API上的使用成本比o1低93%,可以在本地高端工作站上运行,似乎没有达到任何疯狂的速率限制。简单的数学计算表明,在FP8中,每个1b的活动参数需要1gb的RAM,因此R1需要37gb的RAM。批量处理可以大大降低成本,而更多的计算可以增加每秒的token数,因此在云中进行推理仍然具有优势。还要注意的是,这里的确存在地缘政治动态作用,我认为这并非巧合,因为这是在《星际之门》之后出现的。5000亿美元——我们甚至几乎不认识你。
DeepSeek是/曾是App Store相关类别中的下载量第一。显然领先于ChatGPT;这是Gemini和Claude都无法做到的事情。2)从质量角度来看,它与o1相当,尽管落后于o3。3)算法方面确实取得了突破,使得训练和推理效率大大提高。FP8、MLA和多标记预测的训练非常重要。4)很容易验证r1训练运行只花费了600万美元。虽然这是事实,但它也深深地误导了人们。5)即使他们的硬件架构也很新颖,我会注意到他们使用PCI-Express进行扩展。
细微差别:1)根据技术论文,600万美元不包括「与之前对架构、算法和数据的研究和消融实验相关的成本」。这意味着,如果实验室已经花费了数亿美元进行前期研究,并且可以使用更大的集群,那么用600万美元的运行成本训练一个r1质量的模型是可能的。Deepseek显然拥有超过2048个H800;他们早期的一篇论文提到过1万个A100组成的集群。一个同样聪明的团队不可能只用600万美元就组建一个2000个GPU的集群,并从头开始训练r1。大约20%的英伟达收入来自新加坡。尽管Nvidia公司竭尽全力,但该公司20%的GPU可能并未在新加坡。2)他们进行了大量提炼工作——也就是说,如果没有不受限制地访问GPT-4o和o1,他们不太可能训练出这个模型。正如@altcap昨天向我指出,限制使用领先的GPU,却不采取任何措施应对中国提炼美国领先模型的能力,这有点滑稽——这显然违背了出口限制的目的。既然可以免费获得牛奶,为什么还要买奶牛呢?
结论:1)降低训练成本将提高人工智能的投资回报率。2)短期内,这对训练资本支出或「电力」主题没有积极意义。3)对于当前在科技、工业、公用事业和能源领域「人工智能基础设施」的赢家来说,最大的风险是r1的精简版本可以在高端工作站的边缘本地运行(有人提到了Mac Studio Pro)。这意味着类似模型将在大约两年内在超级手机上运行。如果推理转移到边缘,因为它是「足够好」,我们生活在一个非常不同的世界,赢家也完全不同——即我们所见过的最大的PC和智能手机升级周期。计算在中心化和去中心化之间摇摆了很长时间。4)ASI真的非常接近,没有人真正知道超级智能的经济回报是什么。如果一个基于10万多个Blackwells(o5、Gemini 3、Grok 4)训练的1000亿美元推理模型能够治愈癌症并发明曲速引擎,那么ASI的回报率将非常高,训练成本支出和功耗将稳步增长;戴森球(通常指围绕恒星形成连续外壳的固体结构)将重新成为费米悖论的最佳解释。我希望ASI的回报率很高——那真是太棒了。5)这对那些使用人工智能的公司来说确实是一件好事:软件、互联网等。6) 从经济角度来看,这极大地提高了分销和独特数据的价值——YouTube、Facebook、Instagram和X。7) 美国实验室可能会停止发布其领先模型,以防止r1中必不可少的提炼过程,尽管在这方面可能已经完全暴露了。即r1可能足以训练r2等。
Grok-3即将问世,可能会对上述结论产生重大影响。这可以说是自 GPT-4 以来对预训练规模法则的首次重大考验。就像通过强化学习将v3变成r1需要几周时间一样,提高Grok-3推理能力所需的强化学习可能也需要几周时间。基础模型越好,推理模型应该越好,因为三个缩放定律是乘积的——预训练、后训练期间的强化学习和推理期间的测试时间计算(强化学习的函数)。Grok-3已经证明它能够完成超越o1的任务——参见Tesseract演示——超越的程度有多高将非常重要。套用《双塔奇兵》中一位无名兽人的话来说,也许很快就能重新吃上肉了。时间会证明一切,「事实胜于雄辩,我会改变主意。」
不过美股投资分析师徐老猫认为,周一由于DeepSeek造成的抛售是一种过度反应。AI长期增长叙事仍然完好无损,而且可以说现在比以往任何时候都更强大。经济学中有个杰文斯悖论,认为资源利用效率的提高往往会增加(而不是减少)该资源的总体消耗,因为更高的效率会降低使用资源的成本,从而导致对资源的需求增加。
这发生在蒸汽机的煤炭使用上。蒸汽机效率的提高降低了单位产出的煤炭消耗。然而也使燃煤技术更具经济吸引力,导致更广泛的采用,最终增加了总体煤炭消耗。这发生在互联网上,随着计算机越来越小和便宜,上网基本免费,人人都有电脑,人人全天候接入互联网。
现在AI也如此。随着AI模型训练和推理成本的大幅下降,越来越多的公司和个人会构建自己的AI模型,AI在全球范围内普及渗透到社会方方面面。
 5
5
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。


24小时热文


 SEC主席九论AI与加密创新:牢记任务、回归使命
SEC主席九论AI与加密创新:牢记任务、回归使命数字新财报
 通胀裂变下的美国经济未来
通胀裂变下的美国经济未来周子衡

 x402的v2版本
x402的v2版本Block unicorn

 美国SEC手把手教你怎么托管加密资产
美国SEC手把手教你怎么托管加密资产金色财经
 为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析
为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析Stablehunter


- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部