

 Android & iPhone
Android & iPhone“源神”DeepSeek 突破H800性能上限 FlashMLA重磅开源 算力成本还能降

量子位
刚刚
来源:量子位
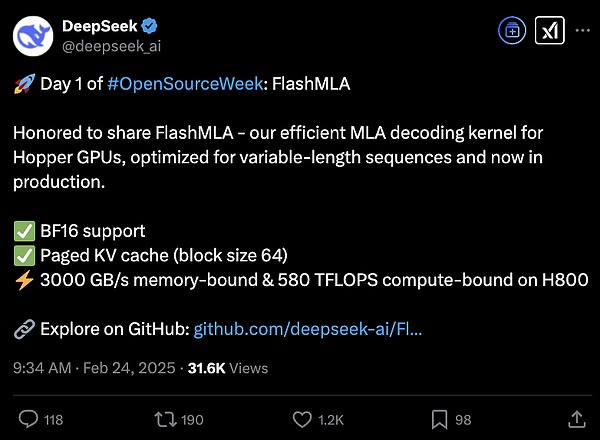
DeepSeek开源周第一天,降本大法公开——
FlashMLA,直接突破H800计算上限。
网友:这怎么可能??

它是为Hopper GPU开发的高效MLA解码内核,专门针对可变长度序列进行了优化,目前已经投入生产。
MLA,正是DeepSeek提出的创新注意力架构。从V2开始,MLA使得DeepSeek在系列模型中实现成本大幅降低,但是计算、推理性能仍能与顶尖模型持平。
按照官方介绍来说,FlashMLA使用之后,H800可以达到3000GB/s内存,实现580TFLOPS计算性能。
网友们纷纷点赞:向工程团队致以崇高的敬意,从Hopper的张量核中挤出了每一个FLOP。这就是我们将 LLM 服务推向新前沿的方式!

已经有网友用上了。
开源第一天:FlashMLA
目前GitHub页面已经更新。短短一小时,Star星数已经超过1.2k。
此次已经发布:
支持BF16;
分页KV缓存,块大小为 64
快速启动:
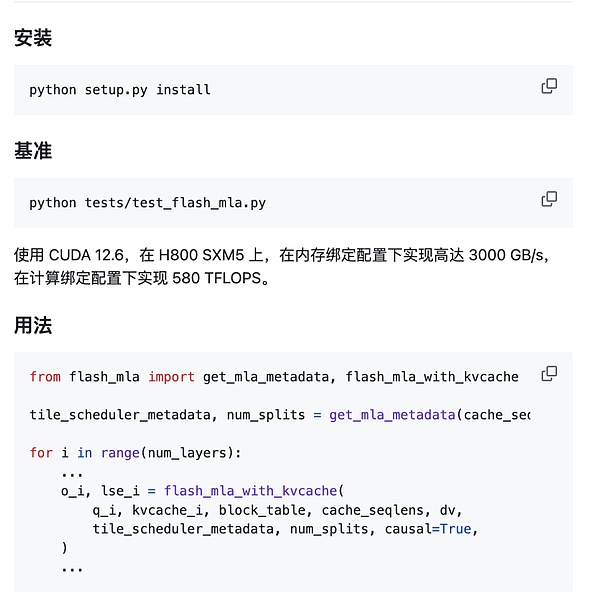
环境要求:
Hopper GPU
CUDA 12.3 及以上版本
PyTorch 2.0 及以上版本
在项目的最后,它还表示,这是受到了FlashAttention 2&3和英伟达CUTLASS项目的启发。

FlashAttention是能实现快速且内存高效的精确注意力,主流大模型都有在用。最新的第三代,可以让H100利用率飙升至75%。训练速度提升1.5-2倍,FP16下计算吞吐量高达740TFLOPs/s,达理论最大吞吐量75%,更充分利用计算资源,此前只能做到35%。
核心作者是Tri Dao,普林斯顿大牛,Together AI的首席科学家。
而英伟达CUTLASS是CUDA C++ 模板抽象的集合,用于在 CUDA 内实现高性能矩阵-矩阵乘法 (GEMM) 和所有级别和规模的相关计算。
MLA,DeepSeek基本架构
最后再来说说,MLA,多头潜在注意力机制,DeepSeek系列模型的基本架构,旨在优化Transformer模型的推理效率与内存使用,同时保持模型性能。
它通过低秩联合压缩技术,将多头注意力中的键(Key)和值(Value)矩阵投影到低维潜在空间,从而显著减少键值缓存(KV Cache)的存储需求。这种方法在长序列处理中尤为重要,因为传统方法需要存储完整的KV矩阵,而MLA通过压缩仅保留关键信息。
V2版本中,这一创新性架构把显存占用降到了过去最常用的MHA架构的5%-13%,实现了成本大幅降低。它的推理成本仅为Llama 370B的1/7、GPT-4 Turbo的1/70。
而在V3,这一降本提速就更为明显,直接让DeepSeek吸引全球目光。
也就在今天,DeepSeek-R1 在HuggingFace上获得了超过10000个赞,成为该平台近150万个模型之中最受欢迎的大模型。
HuggingFace CEO发文公布了这一喜讯。
The whale is making waves!鲸鱼正在掀起波浪!

好了期待一下,接下来的四天会发些什么呢?
 3
3
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。

24小时热文


 SEC主席九论AI与加密创新:牢记任务、回归使命
SEC主席九论AI与加密创新:牢记任务、回归使命数字新财报
 通胀裂变下的美国经济未来
通胀裂变下的美国经济未来周子衡

 x402的v2版本
x402的v2版本Block unicorn

 美国SEC手把手教你怎么托管加密资产
美国SEC手把手教你怎么托管加密资产金色财经
 为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析
为什么投资人都在抢预测市场?Polymarket、Kalshi、Opinion全解析Stablehunter


- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部